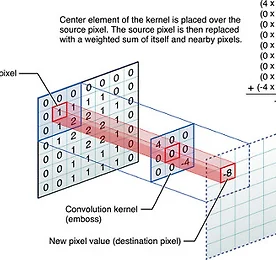
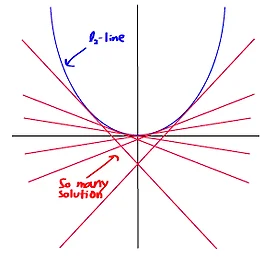
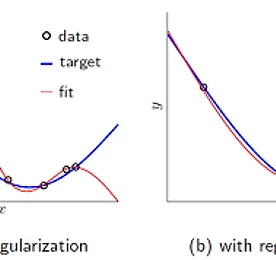
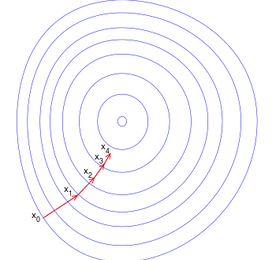
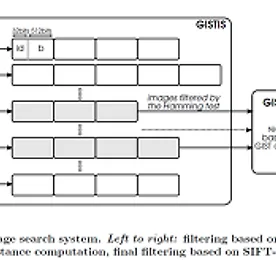
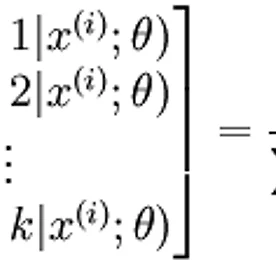Research 썸네일형 리스트형 Softmax Regression [펌] http://eric-yuan.me/softmax/ Softmax RegressionBy ERIC | Published: FEBRUARY 28, 2014WHAT IS SOFTMAXSoftmax regression always as one module in a deep learning network, and most likely to be the last module, the output module. What is it? It is a generalized version of logistic regression. Just like logistic regression, it belongs to supervised learning, and the superiority is, the class labe.. 더보기 convolutional neural network 무식하게 분석하기 - 1 convolutional neural network 무식하게 분석하기 입니다. 이 포스트는 그 첫번째이고, 저도 처음 공부하는거라 틀린것이 매우 많을꺼고 이해못하는 것이 존재합니다. 또한 잘못 이해할수도 있겠죠^^; 하지만, 현재는 그냥 넘어갈지언정 언제가 새로운 자료를 찾아내거나 새롭게 이해하면 그때그때 업데이트 할것입니다. 즉, 이 포스트가 공개될지라고 완성본은 절대 아니라는 점을 기억해두시기 바랍니다. 최근 이미지 분류의 Hot 이슈는 머니머니해도 CNN기반의 Deep Learning입니다. 거의 꼭 알아야하는 수준으로 발전하고 있어서 저도 공부좀 해볼랍니다. 여기서는 초보인지라, 하나의 CPU기반 오픈소스를 분석해가면서 웹의 다른 이런저런 자료를 찾아가면서 이해할것같네요. 기본 소스 : https.. 더보기 l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm 원문 : http://rorasa.wordpress.com/2012/05/13/l0-norm-l1-norm-l2-norm-l-infinity-norm/ I’m working on things related to norm a lot lately and it is time to talk about it. In this post we are going to discuss about a whole family of norm.What is a norm?Mathematically a norm is a total size or length of all vectors in a vector space or matrices. For simplicity, we can say that the higher the norm is.. 더보기 L1 minimization 원문 : http://funmv2013.blogspot.kr/2014/01/l1-minimization.html L1-min 문제는 부족 제한(under-constrained)된 선형 시스템 b=Ax의 해를 구하는 방법 중의 하나이다[1]. 관찰 벡터 b의 요소 수가 미지수 벡터 x의 요수 수보다 작기 때문에 A, b가 주어질 때, x를 구하는 것은 non-trivial linear solver 문제이다. 만일 x가 충분히 sparse하다면(즉, 표준 축(canonical coordinate)에서 요소의 대부분이 0이라면) x값은 minimum l1-norm을 계산함에 의해 얻어진다(주1): min ||x||1, subject to b=Ax x 실제로는 observation b는 noise를 포함하므로 .. 더보기 Machine Learning (Regularization) 원문 : http://enginius.tistory.com/476 1. Regularization Regularization은 말 그대로 제약이다. 기계 학습에서 무엇을 왜 어떻게 제약하는지에 대해서 알아보자. 직관적으로 생각하면, 어떤 문제를 해결하는 분류기를 찾고 싶을 때, 해당 분류기가 들어있는 통이 너무 커서 적절한 답을 찾기 힘들 때, 분류기들을 일단 채에 한번 걸른 후에 걸러진 것들 중에 답을 찾는 것과 비슷하다. 채의 구멍의 크기, 혹은 모양이 서로 다른 regularization을 의미한다. (정확한 비유는 아니다.) 조금 수학적으로 써보면, 우리에게 들어오는 데이터 y=f+ϵ는 에러 ϵ 이 들어가있다. 그래서 우리의 모델은 에러를 같이 학습하려는 경향이 있다. 그래서 in-sample e.. 더보기 자연어 기계학습의 혁명적 진화 - Word2Vec에 대하여(펌) http://www.moreagile.net/2014/11/word2vec.html 2014년 11월 19일 수요일자연어 기계학습의 혁명적 진화 - Word2Vec에 대하여 기계학습의 여러 분야중에서도 자연언어 처리는 가장 흥미진진하고 응용분야가 넓다. 하지만 이 분야의 연구 진행은 토론토 대학의 교수이자 구글에서 인공지능을 연구하고 있는 인공지능 분야의 거장인 Geoff Hinton이 reddit에서 진행된 질의답변 이벤트에서 지적한 바와 같이 반세기 가까이 벨 연구에서 진행된 연구들의 재탕에 지나지 않는 답보 상태에 있는 실정이다. 여기에 최근 주목할만한 한가지 흐름이 나타났기에 이번 포스팅에서 소개해 보고자 한다. 출처 deeplearning4j Word2Vec Word2Vec는 구글의 연구원인 T.. 더보기 Probabilistic Latent Semantic Analysis, PLSA 참조 : http://parkcu.com/blog/probabilistic-latent-semantic-analysis/Probabilistic Latent Semantic Analysis, PLSA| June 12, 2013 12:22 pm | | Categories : Concepts and Techniques, Data Science |Topic model문서들의 집합에서 topic들을 찾아내기 위한 모델로, 눈에 보이는 observation, 즉, given data에 대해 통계적인 방법을 사용하여 모델을 생성하고, 새로운 데이터에 대해서 해당 모델을 적용시켜 원하는 문제를 해결한다. 위에 그림에서 power라는 단어는 정치 토픽으로 쓰여 “국력”을 나타내는 것을 확인할 수 있다. 하지만 powe.. 더보기 orthogonal matrix = 직교 [출처] http://www.ittc.ku.edu/~jstiles/220/handouts.htm * orthogonal ?** 서로 곱해서 적분을 했을 때 0** 공간좌표축의 예를 들어 해석한 경우이다. x,y,z 축은 서로 직교** orthogonal이란 두개이상의 신호가 서로 convolution을 했을 때 0이 되는 경우를 말하며, 두 신호가 섞여도 완벽히 구별할 수 있다는 의미** 직교행렬(直交行列, orthogonal matrix)은 행렬의 각 행벡터들이 서로 직교적인 그리고 크기가 1인, 즉 두 행벡터의 내적이 항상 0이고 각 행벡터의 길이가 1인 행렬을 의미 * ref[1] http://www.rfdh.com/admin/search/search_detail.php3?pid=230&viewnu.. 더보기 Gradient Descent [출처] http://en.wikipedia.org/wiki/Gradient_descent * 기울기 계산* 미분에 의해 계산* 기울기가 - 이면, 하강 즉, local minima 을 향해감, 반면 + 이면 local maxima을 향해감(hill climbing)* NN의 back-propagation에 적용됨, Hidden layer* 에러가 최소가 되는 값을 찾아 최적의 해를 구함.** 최적의 해를 보장하지 않음, local minima/maxima* 두가지 형태 적용 ?[3]** batch ** on-line* x(i+1) = xi+alpha*미분(xi) : maxima, = xi-alpha*미분(xi) : minima** alpha는 learning rate*** 다음 해로 갈 이동거리를 조절.. 더보기 evaluation of gist descriptors for web-scale image search Evaluation of GIST descriptors for web-scale image search Matthijs Douze, Hervé Jégou, Harsimrat Singh, Laurent Amsaleg and Cordelia Schmid Proc. ACM CIVR‘09, July, 2009. * Gist 피처의 성능 평가 논문* Gist는 Gabor를 기본으로 하는 feature,** scale** orientation** 여기에다가 이미지의 공간적 정보를 추가한 것.* 여기에서는 near-duplicate관련 테스트를 주로 한것 같다. ** Gist 피처의 특징에서 보면 좀 안맞는 테스트인듯~** BOW랑의 비교는 좀 아닌듯** 그러나, 위의 그림에서 보면 좀 이렇게 사용한다는 것은 좀 이.. 더보기 이전 1 2 다음