● training 과정
▶ 위의 그림에서
☞ n - 전체 training sample 수
☞ xi - image -> integral image
☞ yi - label : 0, 1
☞ m - positive sample 수
☞ l - negative sample 수
☞ w - weight
☞ T - iteration, optimal 한 classifier 최대 수
☞ t < T (0부터 시작한다면,)
☞ i < 전체 training sample 수
☞ h - weak classifer
☞ f - haar like feature
☞ p - parity (0, 1 or -1, 1)
☞ theta - threshold
☞ e - error rate, false로 예측한 경우에 대한 weight sum
☞ beta - error와 관련 (위의 그림식 참조)
▶ 1. init weight (위의 그림 참조)
▶ 2. training sample loading -> 이때 resize(24x24) & integral image converting
▶ 이후론, training set은 24x24이미지, integral image 형태를 의미함.
▶ 3. generating!! haar like feature
실제 haar like feature를 계산하는게 아니라, 24*24안에 존재할수 있는 모든 feature의 shape를 미리 계산(위치들을 미리 계산한다.
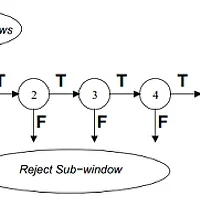
▶ 4. for문(iteration 수는 노가다 = 최적의 iteration을 주어서 반복 찾아야할듯..), 일종의 Stage를 의미하는듯, optimal classifier 찾기
▶ 5. Normalized weight (위의 그림, 1 참조)
▶ 6. for( 모든 features) // greedy feature selection 과정이 무식하게 시작된다.
▶ 7. 이 feature shape과 동일한 위치에서, 모든 sample에 대해 실제 haar like feature를 계산한다.
▶ 8. for( 모든 training set) : feature 접근
▶ 9. 하나의 threshold 즉, feature 선택(for 순으로)
▶ 10. for( 모든 training set) : feature 접근
▶ min error를 선택 (특정 feature & 모든 data내에서) (위의 그림, 2 참조)
▶ 실제로는 pos/neg sample에서 false positive(weak classifier적용)를 판단하여 error를 계산
▶ 잘보면, parity(pos, neg) 는 주어졌고, threshold, feature값을 알고 있으므로 weak classifier를 계산할수 있다.
▶ 위에서 설명한거와 같이 error는 false로 분류될때, weight값을 sum!!
▶ 4가지 경우가 나옴
※ 잘 생각해 보면, 이 의미는 일단 하나 sample을 선택하고 이를기준으로 모든 sample에 정확도(분류 -> false positive rate,,)를 계산한다. 따라서, threshold는 모든 샘플에 대해 반복 판단하고 그중에서 가장 작은 에러를 가지는 것을 선택하는것이다.
※ 즉, 현재 sample을 기준으로 나머지 모든 sample이 잘 분류되는지를 계산한다. 이를 다시 모든 sample에 대해 반복하면 이중에 최소 에러값을 선택하면된다.
▶ 11. 다시 min error를 선택 (모든 feature내에서) (위의 그림, 3 참조)
▶ 선택된 fp(false positive rate)가 0.5 이상되는지 판단.
▶ 12.update weight (위의 그림, 4 참조)
※ 항상 업데이트를 해야하는 것은 아니다. 즉, xi가 잘 분류되었다면, e_i = 0; 그렇지 않으면, e_i = 1; 즉, Beta^(1-e_i)라고 나와있고 이는 분류가 잘 되었을 때, Beta를 곱해서 업데이트하라~란 의미!!
※ 왜? 잘 분류되어 있는데 weight를 업데이트를 해야하는가? -> 잘 보시면, weight는 0~1사이의 값이므로, 원 알고리즘에서 분류가 false일 때는 분류 안된 케이스에 대해하여 가중치를 더준다라고 나왔있다. 따라서, weight가 0~1 사이의 값이므로, 이를 곱하면 분류가 잘된 경우는 weight가 낮아진다. 당연히!! 상대적으로 분류 false인 경우 weight를 높이는 효과를 볼 수 있다.
★ 그런데, 더 중요한건 왜 false 분류된 결과에 대해 가중치를 더 부여하는가??란 의문이 든다?? why??
▶ 13. optimal classifier 저장
▶ min error
▶ 이때 haar feature
▶ min threshold
▶ min false positive
▶ 14. optimal한 판단되면, 이 feature를 제거하고 iteration(<T)
▶ 15. 저장된 것을 결합하면, Strong classifer (위의 그림 참조)
※ 휴 내가 잘 이해했는지 ㅠㅠ
※ 14/02/07 헉 잘 구현했는지 모르겠지만, 약 만개씩 집어넣고 놀리고 나서, 하루 지났는데, 아직도 첫번째 iteration이 진행중이다. ㅠㅠ 모지? 이거?
※ 4/02/13 잘못 이해하고 있는것 같음. Adaboost Training 결과를 이용하여 다시, cascade classifier를 재구성하는것 해야한다는 것 같음?? 영어가 미진하니..ㅠㅠ 암튼 어렵군.이거!!
Next Object Search 가 아니라, Cascade Training!!
'Research > Paper' 카테고리의 다른 글
| [Object Detection] Robust Real-Time Object Detection (4) (0) | 2014.02.14 |
|---|---|
| [Object Detection] Robust Real-Time Object Detection (2) (0) | 2014.01.27 |
| [Object Detection] Robust Real-Time Object Detection (1) (0) | 2014.01.22 |
| [Object Detection] Class-Specific Hough Forests for Object Detection (1) (0) | 2014.01.06 |